|
24.06
|
-
Slides gemaakt voor de eindpresentatie.
-
Aan scriptie geschreven.
|
|
19.06
22.06
23.06
|
-
Cross-validation experimenten uitvoeren, schrijven aan scriptie.
|
|
|
18.06
|
-
Het bepalen van k gaan niet zoals gepland, te veel ambiguiteit in de compactness- en eigenvalue methodes (zie pdf).
-
De dataset-afbeeldingen hebben vaak niet genoeg contrast om te thresholden,
wat nodig is voor het bepalen van de contour. In plaats daarvan worden de locaties van
de gevonden keypoints als puntenwolk genomen, en de standaard-afwijking ellipse met
afmetingen 3*signma wordt eroverheen getekend in de eigenvector-space.
De verhouding sigma2/sigma1 wordt aan de histogrammen toegevoegd.
|



|
|
|
17.06
|
-
Feedback van Arnoud verwerkt in het verslag.
-
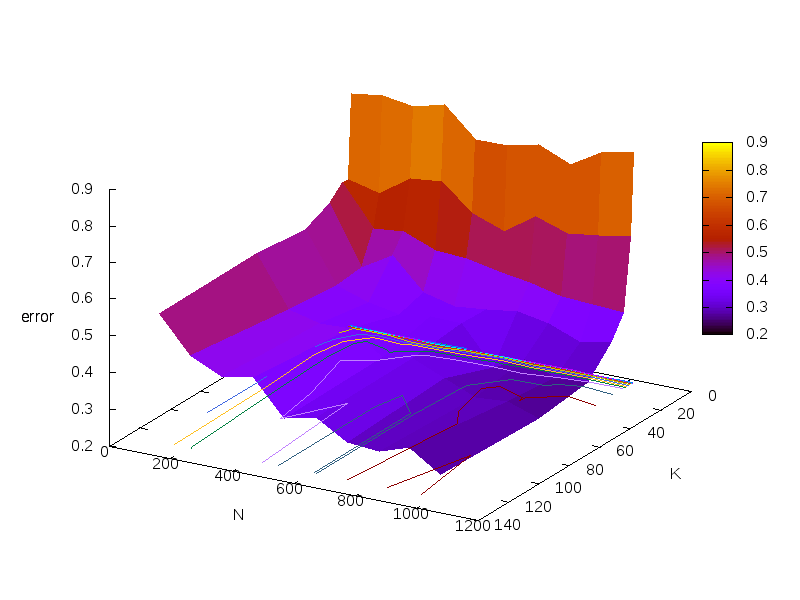
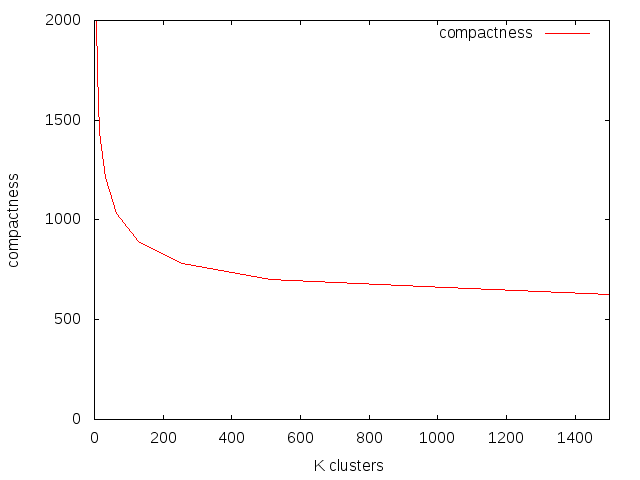
Compactness-elbow zit op k=8000, een te hoge waarde als je kijkt naar error-rate geplot
als functie van K en N. Hier ljkt K in de buurt van 20 al in een elleboog te zitten.
|
|
|
|
16.06
|
-
Feedback-gesprek over academisch Engels, commentaar verwerkt in het verslag
-
Niet de 'ik doe' vorm gebruiken, maar de passieve vorm 'wordt gedaan'
-
Korte zinnen samenvoegen.
|
|
|
12.06
|
-
C++/Java framework gemaakt om met WEKA meerdere tests automatisch te kunnen doen.
|
|
|
11.06
|
-
Eigen implementatie nearest-neighbor voldoet niet meer, verder me WEKA
-
WEKA
Nearest Neighbor en
Wiki voor java
-
Weka save output (vanuit SimpleCLI):
-
java weka.classifiers.lazy.IBk -K 1 -t data/histograms_train.arff -T data/histograms_test.arff > test.ou
-
Weka vanuit commandline voorbeeld:
-
java -cp weka.jar weka.classifiers.lazy.IBk -K 1 -t ../data/histograms_train.arff -T ../data/histograms_test.arff
|
|
|
10.06
|
-
Extra grote dataset gemaakt om ligging van datapunten te analyseren. 1029 afbeeldingen van 10 objecten
|






|
-
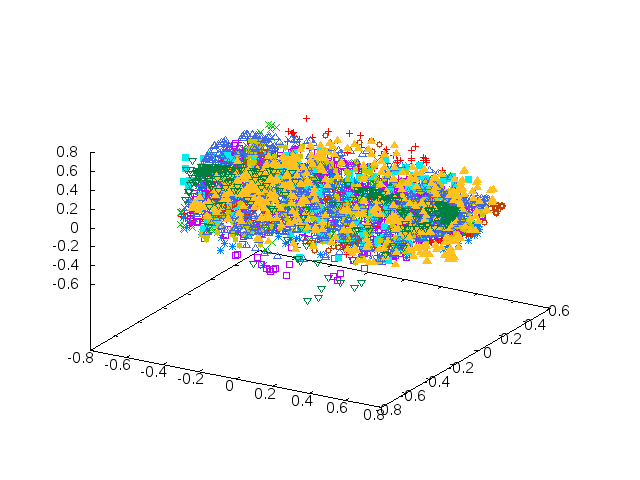
Descriptors gevisualiseerd (met grootste 2 eigenvalues).
Op het oog zijn descriptors niet te sorteren op object-type (links).
Het is dan ook de verdeling van descriptors over ruimte die de histogram bepaalt.
De clusters zijn rechts afgebeeld.
|

|
-
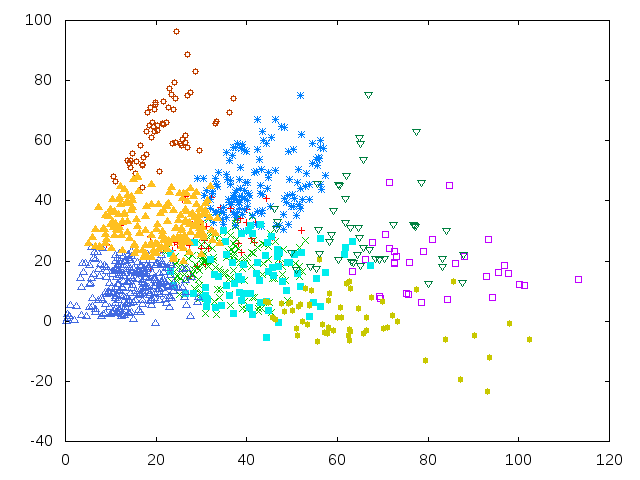
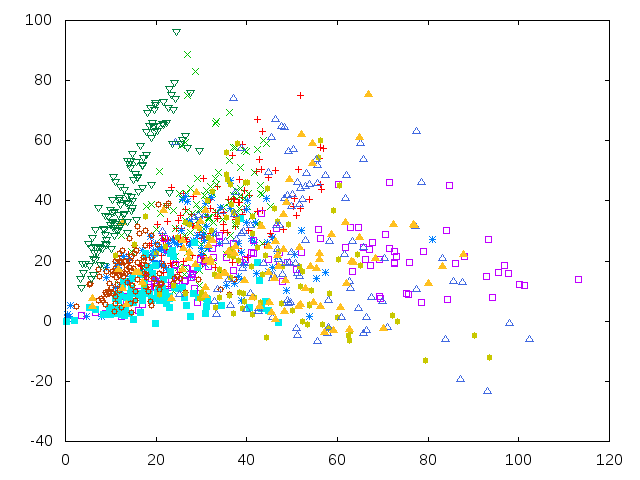
Histogrammen gevisualiseerd (met grootste 2 eigenvalues).
De datapunten van een object-type zijn niet als een cluster te beschrijven (links).
De datapunten van elk object type vormen wel een wolk/sliert die vanaf het oorsprong een bepaalde kant op gaat (rechts).
Hoe verder van het oorspron een punt is, hoe meer descriptors er zijn gevonden in de afbeelding.
Dit zeg waarschijnlijk iets over scherpte kwaliteit van de afbeelding.
|
|
|
|
09.06
|
-
Assignment 9 bijgewerkt adhv feedback over Assignment 8.
-
Twee verschillende manieren geimplementeerd om het aantal clusters te bepalen
-
k=
√ N/2
-
Voor een range van waardes van k wordt de cluster-compactness berekend.
De trade-off punt is de elleboog van de curve. De bijbehorende k wordt gebruikt.
|
|
|
|
05.06
|
-
Assignment 9 uitgebreid en ingeleverd.
-
Begonnen aan onderzoeksmethode-sectie.
-
Werkversie geupload (zie link bovenaan).
|
|
|
04.06
|
-
Introductie geschreven voor de scriptie (Assignment 9).
-
Begonnen aan de structuur van de rest van de scriptie.
|
|
|
03.06
|
-
Gesprek met Arnoud over voortgang:
-
Plan voor de rest van de maand is om het algemene idee van de Bag-of-Words methode uit te breiden op vier gebieden.
-
Opbouwen van dataset adhv variantie, in plaats van willekeurug datapunten toevoegen.
-
Ook andere features gebruiken naast de SURF Keypoints (bijvoorbeeld smARTLab features).
-
Bepalen/berekenen van het aantal clusters en visualisatie van de geclusterde dataset (mbhv PCA).
De resultaten hiervan kunnen worden vergeleken met de resultaten van de vuistregel-k
(k=
√ N/2
)
-
Classificatie-resultaat van andere classificatie-algoritmes (neural networks) tov SVM.
-
Schrijven tegelijkertijd met implementeren/experimenteren. Ongeveer 1 pagina per dag, in totaal ongeveer 30 paginas.
|
|
|
01.06
|
-
Literature-review geschreven voor Assignment 8.
|
|
|
29.05
|
-
Voortgang-presentatie gehouden.
|
|
|
28.05
|
-
Slides gemaakt voor de voortgang-presentatie
|
|
|
26.05
|
-
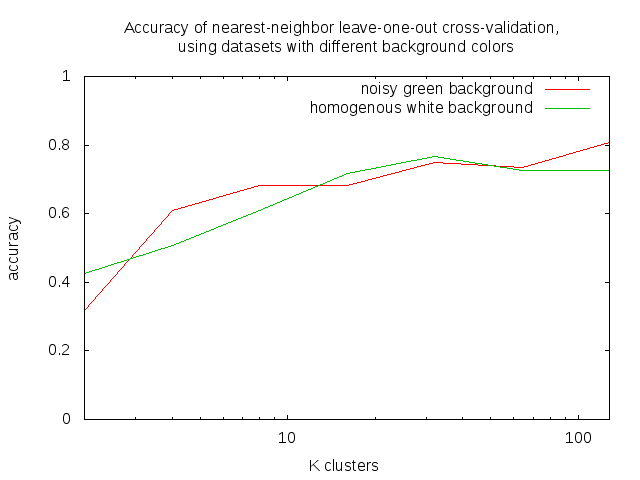
Nieuwe dataset gemaakt met witte achtergrond, met de fellere lampen van de RoboLab aan.
Nog steeds zijn er grote verschillen in licht-intensiteit tussen opeenvolgende afbeeldingen.
-
Mij laptop (MSI, 2.3Ghz Dual Core, 4GB RAM) houdt het niet bij als er meerdere intensieve ros-nodes actief zijn.
Ik heb de Xtion en de 10 @Work-objecten mee naar huis genomen om op een sneller PC verder te werken.
-
In tegenstelling tot de dataset met groene achtergrond,
leidt grotere licht-intensiteit bij een witte (en homogene) achtergrond niet tot ruis-keypoints op de achtergrond
|




|
-
Dit is niet als vooruitgang te merken bij de nearest-neighbor resultaten met leave-one-out cross-validation.
(misschien dat de nearest-neighbor methode niet de voordeel benut die de nieuwe database biedt)
|
|
-
De feedback-programma (trainer) uitgetest op de dataset met witte achtergrond
-
Het programma pakt frames van een live-stream van een object en probeert dit object te herkennen in het plaatje.
-
Als het object niet wordt herkend, kan de gebruiker op een knop drukken en wordt de (verkeerd geclassificeerde) frame toegevoegd aan de dataset.
-
Nadat dit een vaste aantal (3) keren is gedaan voor een bepaald object, vraagt de trainer-programma om het object te presenteren waarvoor het vorige object het meest (verkeerd) is aangezien.
-
Op den duur leidt dit tot eindeloze loops tussen twee objecten die erg op elkaar lijken
-
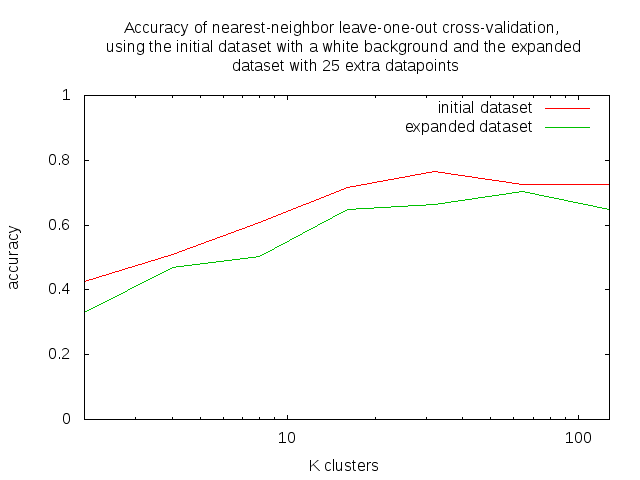
Ook uit de cross-validation resultaten lijkt dit de dataset niet beter te maken.
Dit kan ook komen door de manier waarop wordt besloten van welke objecten er nieuwe datapunten worden toegevoegd.
De accuracies na het toevoegen van 25 nieuwe datapunten:
|
|
|
|
25.05
|
-
Feedback programma gemaakt:
-
Een dataset van de objecten wordt gegeven om mee te beginnen (120 images)
-
Van een live-stream van (camera)images van eenzelfde object worden frames gepakt en geclasificeerd met een simpele nearest-neigbor algoritme. De verkeerd geclassificeerde images worden (bij keypress) toegevoegd aan de dataset, en de BoW-histogrammen worden opnieuw uitgerekend voor de hele dataset.
-
Dit eigenlijk is een slimme manier om een dataset uit te breiden. Alleen datapunten die waardevolle (nieuwe) informatie bevatten worden toegevoegd. Het programma is getest met de initiele dataset van 120 images. Nieuwe objecten worden aangeboden en na ongeveer 10 keer een datapunt toevoegen kan het programma de nieuwe objecten herkennen en onderscheiden van de 10 oude objecten. Nog niet getest op de ROckin-objecten, Science Park is dicht.
-
Het zou interessant kunnen zijn om te kijken of het ook werkt zonder initial dataset. Dus de hele dataset opbouwen op deze manier.
-
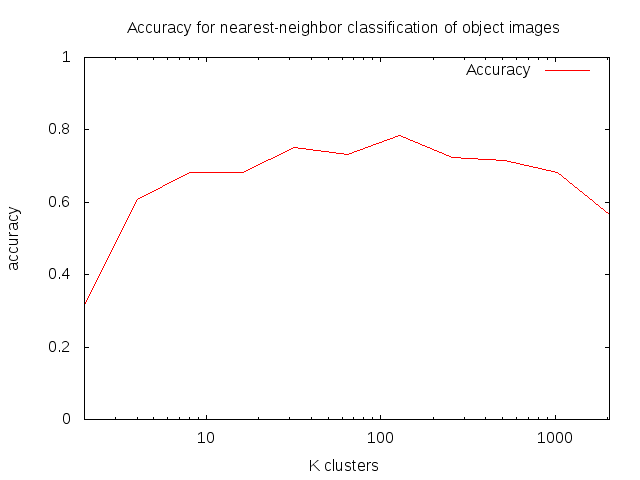
Experimenten gedaan met de waardes van k voor het clusteren. Hogere waardes vertragen het programma drastisch. De beste waarde lijkt tussen 10 en 100 te zitten. Voorlopig werk ik verder met 64. (64 clusters voor 28110 datapunten)
|
|
|
|
21.05
|
-
Rockin dataset bekeken. Voorlopig niet gebruiken ivm lage kwaliteit van RGB object.
-
Programma herschreven om handiger te maken voor experimenten:
-
Met SURF wordenimage descriptors berekend
-
Met kmeans worden alle descriptors geclusterd voor K centroids
-
Er worden K-dimensionale histogrammen gemaakt per afbeelding
-
Met een simpele nearest-neighbor algoritme wordt elke histogram geclassificeerd als het object van zijn nearest-neighbor
|
|
20.05
|
-
als catkin_make per se een source-file wil die verwijderd is, verwijder devel/ en build/ en, doe catkin_make clean en catkin_make opnieuw.
-
parameters in kmeans: maxcount (10000) en epsilon (0.0001)
-
Classificatie van histogrammen met simple nearest-neighbor geeft varierende resultaten voor dezelfde parameter, afhankeijk van de volgorde. Bijv met K=64 is de accuracy 0.775. Met K=32 en dan K=64 in dezelfde runtime heeft K=64 accuracy 0.776. Di komt waarschijnlijk door een random-factor in de kmeans clustering algoritme.
-
Opgelost door KMEANS_USE_INITIAL_LABELS te gebruiken, met een niet-lege labels-matrix als input.
|
|
18.05
|
-
Veel meer SURF-keypoints als de getrasholde afbeelding wordt gebruikt. Bijv:78 ipv 44 bij donkere afbeelding, 1937 ipv 128 bij lichtere afbeelding met parameter threshold = 100.
-
OpenCV Mat element: Mat.at<type>(index)
-
clustering en histogram opbouw functionaliteit toegevoegd aan code (parameter K)
-
Met een simpele nearest-neighbor algoritme is de classificatie-accuracy voor de object type 0.623 (zonder thresholding) en 0.458 (met thresholding)
|
|
14.05
|
-
Logboek omgezet naar HTML, geupload
-
Begonnen met framework voor de ROS-C++ programma voor object-recognition.
-
Groene achtergrond is moeilijk te onderscheiden van de objecten. Zilverkleurig metaal weerkaatst groen en ziet er hetzelfde uit als de achtergrond.
|


|
-
Bij gebruik van "opencv2/nonfree/features2d.hpp", zoals SiftFeatureDetector kan catkin_make niet compilen:
/usr/local/lib/libopencv_nonfree.so.2.4.10: undefined reference to `cv::ocl::integral(cv::ocl::oclMat const&, cv::ocl::oclMat&)'
Ook op (MSI) laptop geprobeerd, zelfde probleem.
-
Standalone compilen (cmake zonder ROS) lukt wel!
-
Workaround: OpenCV opnieuw cmake-en zonder OPEN_CL ondersteuning. In openvc/build
-
sudo make uninstall
-
sudo make clear
-
sudo cmake -D WITH_OPENCL=OFF -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local ..
-
sudo make -j5
-
sudo make install
-
Loze compile warning: CMake Warning at object_recognition/CMakeLists.txt:32 (add_executable):
Cannot generate a safe runtime search path for target recognition because
files in some directories may conflict with libraries in implicit
directories
-
SurfFeatureDetector werkt op het oog beter dan SiftFeatureDetector. Meer KeyPoints die diverser zijn in omvang.
parameters: hessianThreshold, nOctaves, nOctaveLayers, extended, upright
-
Grote variatie in verlichting in de dataset-images. Twee opeenvolgende images hebben verschillende aantal key-points:
|


|


|
|
|
13.05
|
-
Twee datasets gemaakt van 10 objecten:
-
12 rotatie-bins per object, even verdeeld over de 360 graden. Rotatie alleen om een vaste z-as van het object.
-
12 "willekeurige" poses van het object, rotaties over alle
-
Datasets zijn alleen RGB. Pointclouds kunnen alleen van afstand (80cm) worden gemaakt, en dan is de RGB kwaliteit niet zo goed.
-
Datasets zijn gemaakt op groene achtergrond, lichval varieert.
|


|
|
|
11.05
|
-
Point cloud dataset wordt te groot en te slechte kwaliteit. De .stl modellen kunnen worden geladen als pointclouds. Een pointcloud dataset maken is niet nodig.
|
|
08.05
|
-
catkin workspace in Dropbox gemaakt
-
cmake tutorial gedaan, CMake Editor voor Eclipse geinstalleerd
-
introductie-tutorial gedaan voor PCL in ROS
-
Programma downsamplet point-cloud en publiceert output topic. parameters: LeafSize (3 x 0.2).
-
Eclipse crasht vaak ivm geheugen.
Oplossing
--launcher.XXMaxPermSize256m --> 512m
-Xms40m --> 1024m
-Xmx384m --> 1024m
-
Eclipse : ros en pcl directories toegevoegd aan "Paths and Symbols"
-
Rosbag gemaakt van ongeveer 60 seconden points+rgb data. Gebruik topic_toolsthrottle om een topic te echoen met een andere frequentie.
-
ROS programma geschreven om op keypress een pointcloud (.pcd) en een rgb-image (.jpg) op te slaan.
-
Keyboard command afluisteren met keyboard/Key.msg types.
-
Pointcloud wegschrijven met PCL
-
RGB image wegschrijven met OpenCV
-
Een .pcd file is ongeveer 5mb. Om van 10 objecten 16 rotatie-bins per object te maken is 160*5=800mb nodig.
|
|
07.05
|
-
Xtion met PCL werkt slecht, crasht vaak.
-
ROS installeren
-
Ros Ros Tutorial
-
ASUS Xtion Pro Live heeft product-id 0x0601: (lsusb -v -D /dev/bus/usb/002/003 | grep id), of andere usb bus/device
-
Xtion 0601 heeft
openni2 nodig
-
sudo apt-get install ros-indigo-openni2-launch
-
sudo apt-get install ros-indigo-openni2-camera
-
roslaunch openni2_launch openni2.launch
-
openni2 node die data publiceert
-
"Warning: USB events thread - failed to set priority. This might cause loss of data...", maar alles werkt. Loze waarschuwing.
|
|
06.05
|
-
Capture-programma werkt niet voor RGB images. Nieuw programma geschreven met openni_wrapper::Image.
-
Werkt wel op laptop, maar te langzaam in combinatie met pointcloud.
-
Op PC : Warning: USB events thread - failed to set priority. This might cause loss of data...
|
|
04.05
|
-
RGB/PointCloud dataset-capture programma gemaakt, maar geen Xtion ivm dodenherdenking.
-
Functie geschreven voor het vinden van grootste object in een foto en maken van een bounding box
|
|
30.04
|
|
|
29.04
|
|
|
24.04
|
-
Presentatie gegeven op SCP
-
Onderzoeks-opzet geschreven
|
|
23.04
|
-
Presentatie voorbereid, slides gemaakt
|
|
22.04
|
-
Video-lecture van UCF CRCV
|
|
21.04
|
-
Literatuur opgezocht over Bag of Words approach
-
Bestudeerd: Gabriella Csurka, Christopher Dance, Lixin Fan, Jutta Willamowski, and Cédric Bray. Vi-
sual categorization with bags of keypoints. In Workshop on statistical learning in com-
puter vision, ECCV, volume 1, pages 1-2. Prague, 2004.
-
Video-lecture van UCF CRCV
-
Interest Point Detection
-
Scale-invariant Feature Transform
|
|
20.04
|
-
Literatuur opgezocht over Hough Transform: ellipses, 3D
|
|
17.04
|
-
Problem definition aangepast nav feedback.
|
|
16.04
|
-
Feedback terug van Arnoud
|
|
15.04
|
-
Assignment 4:
-
Problem definition opgesteld.
-
Literatuur opgezocht mbh keywords.
-
Beschrijving geschreven van 6 artikelen met link naar eigen project.
-
Problem definition naar Arnoud gestuur
|
|
13.04
|
|
|
10.04
|
-
Team description papers gelezen: beknopte inhoud, geen referenties naar code
-
Assignment 4: keywords bedacht
|
|
09.04
|
-
Assignment 3: bijgevoegde artikel gelezen en beoordeling/commentaar geschreven
|
|
08.04
|
-
College bijgewoond
-
Met Aroud gesproken over opzet project:
-
Het project is eerder gedaan door verschillende teams (oa van de UVA)
-
Project hoeft niet strict volgens Rockin Competitions regels
-
Kinect, Kinect 2 en Xtion beschikbaar als sensor
-
Eigen laptop kan gebruikt worden voor rekenwerk
-
Eindverslag beschrijft:
-
Resultaat (precision, confusion-matrix etc.)
-
Ruimte voor koppeling aan Visual Servoing (bijv: ROS-compatible?)
-
Rockin Competitions Wiki bestudeerd, nodige bestanden gedownload
|
|
07.04
|
-
Project "RoCKIn @ Work Object recognition" toegewezen
-
Arnoud Visser gemaild voor een afspraak
|
|
02.04
|
-
Assignment 2 geschreven nav bijgevoegde artikelen
-
Assignment 1: tenders geschreven voor "RoCKIn @ Work Object recognition" en "Semi-Supervised Learning met auto-encoding neural networks"
|
|
01.04
|
-
College bijgewoond
-
Artikelen gelezen van Simon en March-Smith
|
|
30.03
|
|